Within a typhoon, another TokyoR Meetup! … well not really it turned out to be a false alarm and the weather was a wonderful 30 degrees Celsius with 800% humidity as usual in Tokyo. My gripes with the weather aside this month’s meetup was held at Cresco, an IT management strategy company, in their headquarters in Shinagawa, Tokyo.

In line with my previous round up posts:
I will be going over around half of all the talks. Hopefully, my efforts will help spread the vast knowledge of Japanese R users to the wider R community. Throughout I will also post helpful blog posts and links from other sources if you are interested in learning more about the topic of a certain talk. You can follow Tokyo.R by searching for the #TokyoR hashtag on Twitter.
Anyways…
Let’s get started!
BeginneR Session
As with every TokyoR meetup, we began with a set of beginner user focused talks:
Main Talks
ill_identified: Econometrics vs. Machine Learning
@ill_identified gave a talk on a more general industry topic rather
than about R specifically by talking about the differences between econometrics and
machine learning/A.I. To start off he listed some good resources (in
English) to read from the economics/econometrics side of the discussion:
- Machine Learning: An Applied Econometric Approach - S. Mullainathan & J. Spiess
- Big Data: New Tricks for Econometrics - H. Varian
- Machine Learning Methods Economists Should Know About - S. Athey & G. Imbens
From looking at the methods that both fields use like multiple linear regression, logistic regression (GLMs), Monte-Carlo Markov Chain (MCMC), non-parametric regression, etc. it seems as though they might be the same thing… but an important distinction can be made in that:
- Economics/Econometrics == Causal Inference
- Machine Learning == Prediction
Frank Harrell in Road Map for Choosing Between Statistical Modeling and Machine Learning as well as Miguel Hernan in Data science is science’s second chance to get causal inference right: A classification of data science tasks discuss this in length if you want to take a look.
@ill_identified then took us through a couple examples of causal
inference from a variety of economics research focusing on the spread
and popularity of Randomized Control Trials (RCTs) and
Difference-In-Differences (DID) in the field.
There was a talk on DID at last year’s Japan.R Conference that you can find here!
From the side of machine learning, Athey (2018) talked about how up to the present, economists have been trying to fit their model to the entirety of the data available to them, leading to potential problems of over-fitting. To counteract this problem Athey notes how the field can learn from machine learning by using cross-validation techniques and penalized models.
For causal inference from the machine learning side of the discussion,
@ill_identified talked about Judea Pearl’s answer of Quora to the
question, “What are the differences between econometrics, statistics,
and machine
learning?”.
In the answer, Judea Pearl makes the distinction between standard ML and advanced ML, namely that the former (while specifically including deep learning and neural networks in this category) “fits a function to a stream of data and plays the same role as statistical analysis, taking us from samples to properties of distribution functions.” while the latter “goes beyond distributions onto the process that generates the data, and so, allows us to manage policy interventions and counter-factual reasoning”. He then points to two of his works, 7 Tools of Causal Inference with Reflections on Machine Learning and The Book of Why (written with Dana MacKenzie) for further reading. It is in the former work that Judea Pearl talks about the three levels of the causal hierarchy:
- Level 1: Association
- Level 2: Intervention
- Level 3: Counterfactuals
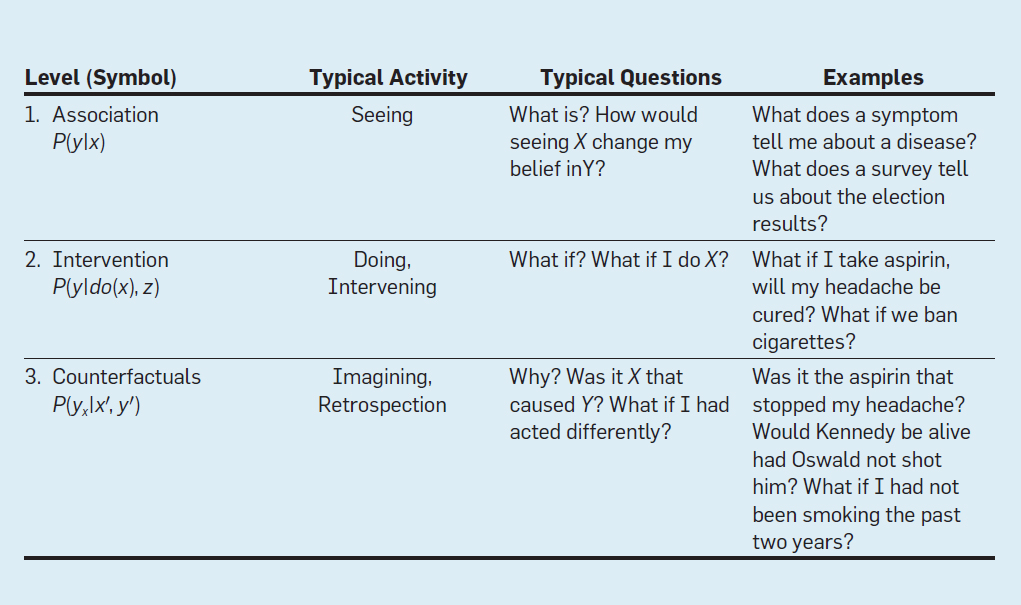
There is a lot of debate centered on “Potential Outcomes” theory posited by Neyman & Rubin versus Pearl’s “Causal Graphs/SEM” approaches in the past while Andrew Gelman has also talked about the issue here (2009) and here (2011). Very recently, Guido Imbens submitted an article, Potential Outcome and Directed Acyclic Graph Approaches to Causality: Relevance for Empirical Practice in Economics that discusses this in length that is probably worth checking out as well!
From the Rubin side of the debate Guido Imbens, Susan Athey, and Viktor Chernozhukov stand out as the primary researchers.
Athey:
- Causal Tree/Causal Forest - Wager & Athey (2018)
- Generalized Random Forest - Athey et al. (2019)
- {causalTree} R package
Chernozhukov:
- Double/Debiased/Neyman Machine Learning of Treatment Effects - Chernozhukov et al. (2017)
- Double/Debiased Machine Learning for Treatment and Causal Parameters - Chernozhukov et al. (2018)
- Estimation and Confidence Regions for Parameter Sets in Econometric Models - Chernozhukov et al. (2007)
In the final section @ill_identified went over a few new methods in
A.I./ML that provided some evidence to show that A.I./ML does indeed
have similarities with econometrics mainly through the application of
the structural estimation approach to modeling. A good overview is
Artificial Intelligence as Structural Estimation: Economic
Interpretations of Deep Blue, Bonanza, and AlphaGo - Mitsuru
Igami while you can read about the
specific AIs discussed in more detail below.
kilometer00: R interface to Python
TokyoR organizer and frequent BeginneR session speaker @kilometer00
talked about using Python with R.
To familiarize the audience with Python he went over quite a number of slides showing the similarities and differences in syntax between the two languages.


Next, @kilometer00 talked about the {reticulate} package which allows
you to call Python from R and can provide translation between R and
Python objects (such as R and Pandas data frames or R matrices and NumPy
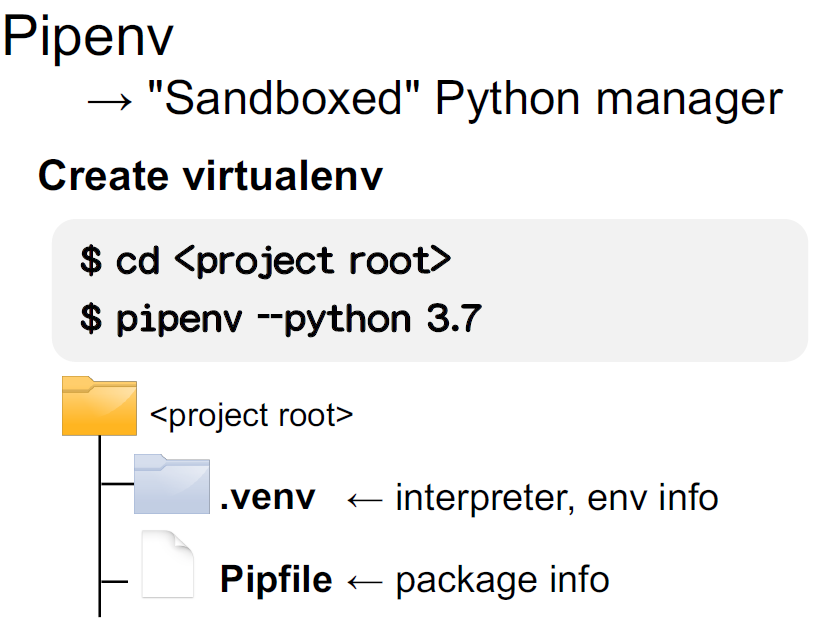
arrays). Using {reticulate} he talked about the importance of having an
isolated and independent environment, to keep Python in a “sandbox”-ed
virtual environment for security and reproducibility. To do this
@kilometer00 likes to use Pipenv.

Once you’re done with all the set-up, you can install {reticulate} from
CRAN and attach your Python virtualenv with reticulate::use_python()
and then you can finally start doing stuff! But be wary of type errors
when you’re coding:

You can also use Python in a R Markdown document by setting the code chunk to run it. With a recent development in RMD you can now also share objects from different languages by putting a prefix in front of the object name!

Funnily enough you can also run R in Python in R:
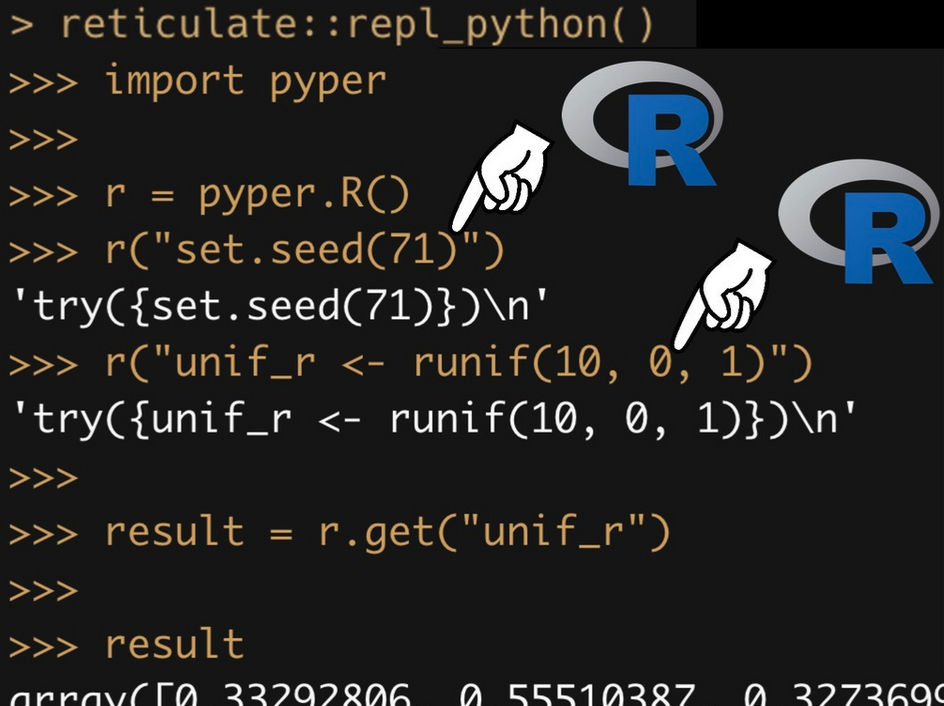
Pythonception!
More resources on {reticulate}:
- {reticulate} package website
- R or Python? Why not both? Using Anaconda Python within R with {reticulate} - Bruno Rodrigues
- R and Python: Using reticulate to get the best of both worlds - Manuel Tilgner
LTs
wkwk_soprano: Creating network graphs with R!
It’s been a while since @wkwk_soprano used R (5 years!) but he’s come
back with aplomb by talking about network graphs at Tokyo.R! Network
graphs are used in all sorts of fields of study including physics,
chemistry, linguistics, and the social sciences. In industry you might
see them as part of a recommendation graph between a customer and
products on sale. Frustrated by the fact that he didn’t have a fun data
set to use the {network} package on, @wkwk_soprano decided to create
his own data set based on his favorite manga, One Piece!
By counting up the times a character appeared in one panel of the manga with another he slowly built up a co-occurrence matrix of all the characters from Volume 1 to Volume 23. It took him about one hour per volume to create this data set, now that’s dedication!

You can find the gum-gum fruits of his labor here.
After creating the data @wkwk_soprano wanted to do some analysis on it
like graph embedding via DeepWalk or Large-scale Information Network
Embedding (LINE). There’s actually a R package called
Rline to implement this method but
he found that it was difficult to install and it hadn’t been updated in
a while so he went with the original C++
implementation from Jian Tang et
al. The result was an output of the distributed representation of all
the characters in the data.

Lastly, @wkwk_soprano wanted to find similarities between One Piece
characters so he used cosine similarity using this code
snippet
which allows you to extract top ‘N’ similar items from network embedding
matrices. Taking a look at some popular characters he was somewhat
disappointed in the results as from his extensive knowledge of the story
he knew some of the character similarities just weren’t right!

More resources on network analysis in R:
- Intro to Network Analysis with R - Jesse Sadler
- Network Centrality in R: An Introduction with {netrankr} - David Schoch
gepuro: Translating tidyverse.org into Japanese!
After being involved in the Japanese translation of Feature Engineering
for Machine Learning: Principles and Techniques for Data Scientists,
@gepuro thought about trying his hand at translating tidyverse.org
in Japanese!
In recent months there have been big changes in major tidyverse
packages such as {tidyr} and {ggplot2} with accompanying articles to
boot. These articles, especially the new pivot functions vignette, are
the ones @gepuro and fellow TokyoR community members such as @Atsusy
have started working on in the past few weeks. To do the translation
there are three key steps:
- Create a Github account
- Log into GitLocalize
- Access the specific GitLocalize repo where your translation project is located
GitLocalize looks like this:
![]()
Once you’re done, you create a “Review Request” which is checked by the
maintainer @gepuro for any errors. He’ll receive the “Review Request”
as a Pull Request on the R Lang Document JA repo and if everything is
OK it’ll be merged in!
There are other ways to contribute to the project as well such as:
- Helping to make the text sound more naturally Japanese
- Create the blogdown website of the Japanese translation
- Create a vocab list of common R terminology in Japanese to use as a reference
- and more!
I enjoyed this talk as it was similar to the talk by Riva Quiroga on translating the “R for Data Science” book and R data sets into Spanish that I heard at user!2019 a few weeks ago (the talk is covered in my blogpost here). If you’re good at English and Japanese you can join the #translation channel on the Tokyo.R slack!
In other news, there was an announcement that this year’s Japan.R Conference will be on December 7th!
Other Talks
- airspace_nobo: Use Python from R!
- kodachan: Proxy authentication with R!
- k871: R in a Traditional Japanese Manufacturing Company!
Food, Drinks, and Conclusion
TokyoR happens almost monthly and it’s a great way to mingle with
Japanese R users as it’s the largest regular meetup here in Japan. We’re
finally taking a break next month so the next meetup will be on
September 28 and it will be a special session in {Shiny}!
Talks in English are also welcome so if you’re ever in Tokyo come join us!