With the arrival of summer, another TokyoR User Meetup! On May 25th, useRs from all over Tokyo (and some even from further afield - including Kan Nishida of Exploratory, all the way from California!) flocked to Jimbocho, Tokyo for another jam-packed session of R hosted by Mitsui Sumitomo Insurance Group.

Like my previous round up posts (for TokyoR #76 and TokyoR #77) I will be going over around half of all the talks. Hopefully, my efforts will help spread the vast knowledge of Japanese R users to the wider R community. Throughout I will also post helpful blog posts and links from other sources if you are interested in learning more about the topic of a certain talk. You can follow Tokyo.R by searching for the #TokyoR hashtag on Twitter.
Unlike most R Meetups a lot of people present using just their Twitter
handles so I’ll mostly be referring to them by those instead. I’ve been
going to events here in Japan for a bit over a year but even now
sometimes I’m like, “Whoahh that’s what
@very_recognizable_twitter_handle_in_the_japan_r_community actually
looks like?!”
Anyways…
Let’s get started!
BeginneR Session
As with every TokyoR meetup, we began with a set of beginner user focused talks:
- Reading in data with R by y_mattu
- Visualization with R by koriakane
- Data analysis with R by kilometer00
Main Talks
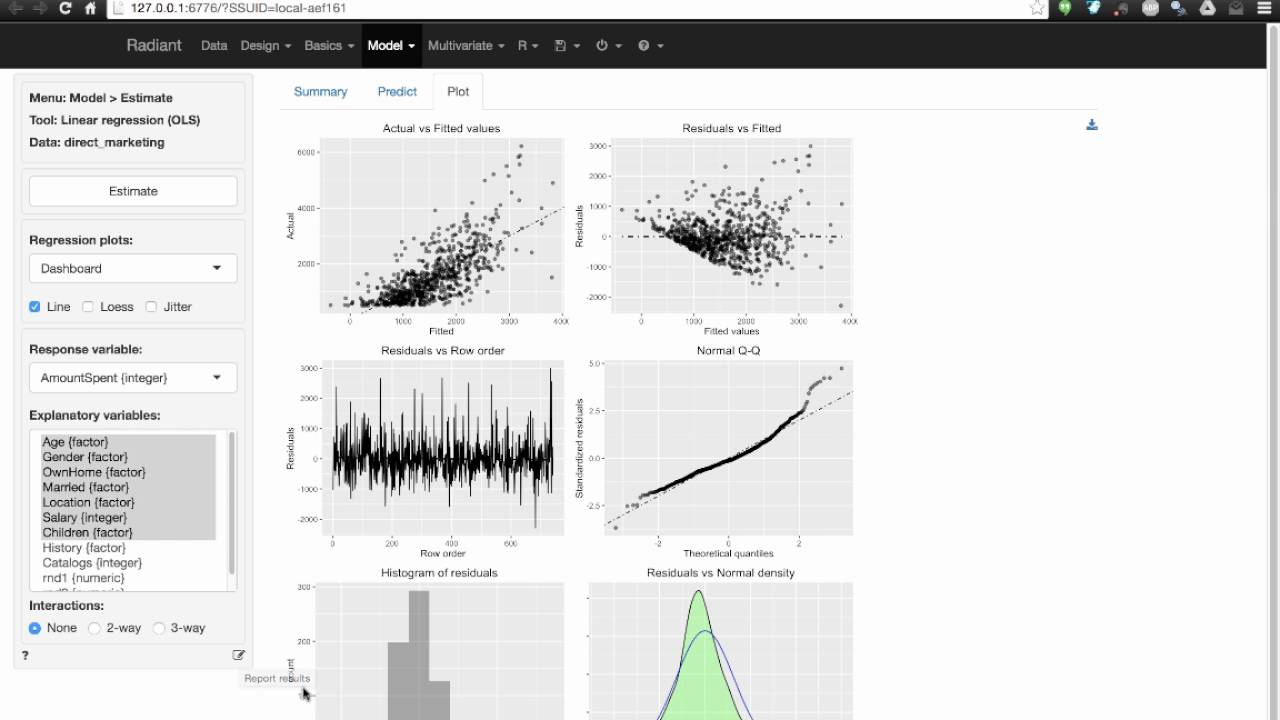
tanakafreelance: Radiant for Data Analysis!
@tanakafreelance talked about
Radiant, which is a
platform-independent browser-based GUI for business analytics that was
developed by Vincent Nijs. It is a tool for business analytics
purposes and is based on Shiny. After installation from CRAN you can
launch it via using radiant::launcher(). Most of this presentation was
a live demo by @tanakafreelance showing a lot of the functionality
offered by Radiant such as creating reproducible reports with R
Markdown, writing your own R code to use within the GUI, creating and
evaluating models (linear/logistic regression, neural networks, naive
Bayes, and more), and design of experiments (DOE)!
You can run it from a variety of set ups from online, offline, on
shinyapps.io, Shiny server, and even on a cloud service like AWS via a
customized Docker container. For a comprehensive introduction to
Radiant’s full capabilities you can check out its awesome website
here, full of videos
and vignettes!
kotaku08: Transitioning a Company to Use R!
@kotaku08 talked about his experiences in data analytics and ways he
pushed for the usage of R at his company, VALUES. One of the first
things he realized upon entering the company was how the skill set of
the team was more of that of data/system engineers rather than data
analysts. After some time he found three big problems with his working
environment that he wanted to solve:
- Mismatch between the tool used and the task needed done
- easy data manipulation with PHP.
- complicated data manipulation with Excel.
- What was this again?! (Illegible! Non-reproducible! Non-reusable!)
- Extremely convoluted Excel formulas that look like they could be
banned by the
Malleus Maleficarum. - Excel sheets only contain the results.
- If it was a visualization task, it was all done in Tableau…
- Extremely convoluted Excel formulas that look like they could be
banned by the
- Data extraction being a painful process…
- Connecting to
Redshiftis a pain!
- Connecting to
While pondering these problems, he came across this
article
from AirBnB that highlighted their transition to building R tools and
teaching R across the company. The key takeaways that @kotaku08 took
from the article was:
- Most analysts at AirBnB use R.
- Intracompany package:
Rbnb. - Efforts put into R education and conducting workshops.
- Data analysis is both efficient AND reproducible!
Taking these lessons to heart he decided to implement #rstats learning
sessions as well as create a company R package! One of the main
functionalities of VALUES’ main R package is being able to access data
from Redshift and in tandem with the various packages in the cloudyr
project has made getting data much more easier for @kotaku08 and his
team.
Another big step was educating fellow employees about #rstats.
For existing employees:
- Spread rumors about how accessing data is much easier with R…
- Those skilled in other scripting languages organically come over to check R out!
For new employees:
- Emphasize how R is THE standard at the company,
- “Graduate hires”, most of whom have no programming experience, are put into R boot camps
- After 3 months of hard work, able to use the
tidyversefor analytical tasks!
As a result of these efforts 80% of employees can now use R and the
internal company package has two new maintainers (both graduate hires!)
to work alongside kotaku08.
Some other resources:
- List of Companies Using R! (With explanatory blogposts/articles)
- Scaling Knowledge at AirBnB
- Enterprise Web Services with Neural Networks Using R and Tensorflow
- “Putting empathy in action: Building a ‘community of practice’ for analytics in a global corporation” - JD Long (at RStudio::Conf 2019)
- itdepends - A dialogue about dependencies
tomkxy: Making Your Code Faster - Introduction to Vectorisation and Parallel Computing (English with demonstrations)
@tomkxy presented in English (he’s a Kiwi that works for RIKEN!) on
vectorizing your code and parallel computing with R. In response to a
lot of the accusations that “R is slow”, Tom talked about different
techniques to use to make your R code faster along with some some
demonstrations (the RMD can be found
here).

One of my key take-aways from this talk was, “Code first, optimize later!”. In that it’s important to not get stuck doing premature optimization, especially if you might not actually need to use the code again anyways! Also, sometimes parallel computing may not always be the fastest solution due to overhead costs associated with setting up clusters and communication between clusters.

In addition, the newly developed “Jobs” pane in RStudio 1.2, released last month, means you can keep being productive even while you have your scripts running in the background. A great resource for those interested is the CRAN Task View for high performance and parallel computing available here.
A few other resources:
- Vectorization in R - Noam Ross
- Chapters 3 & 4 on vectorization of the classic: R Inferno - Patrick Burns
- “What does it mean to write ‘vectorized’ code in R?” - Win-Vector
- The functionals and Optimizing code sections of Advanced R - Hadley Wickham
- Using RStudio Jobs for training many models in parallel - Edwin Thoen
LTs
ill_identified: Guide to MCMC with the bayesplot package!
@ill_identified presented on using Markov chain Monte Carlo (MCMC)
with R, specifically using the bayesplot package. MCMC are a series of
methods that contain algorithms for sampling from a probability
distribution. These methods involve drawing random samples from a target
distributions using algorithms (such as Metropolis-Hastings algorithm,
reversible jump, HMC, etc.) then we attempt to construct a Markov chain
such that its equilibrium probability distribution is as close to our
target distribution as possible by iterating the chain many times.

As I’m not familiar with MCMC very much I won’t go into too much detail
here, however for others unfamiliar with MCMC and Bayesian
inference,@ill_identified provided a nice list of books to get you
started:
- Bayesian Data Analysis - Gelman et al.
- Introduction to Bayesian Statistics with R (Japanese) - Okumura et al.
- Bayesian Modeling with Stan & R (Japanese) - Matsuura et al.
Just recently TJ Mahr, one of the authors
of bayesplot, presented on the package at Chicago SatRDays. You can
check the slides out
here. The new version
of bayesplot, 1.7.0, will also support tidyselect:

Other resources:
- CRAN Task View: Bayesian Inference
- bayesplot vignette: Plotting MCMC draws
- Statistical Rethinking with brms, ggplot2, and the tidyverse - Solomon Kurz
Atsushi776: May I felp you?
@Atsushi776, known in the Japanese R Community for his “headphones”
avatar, created a new package called
felp as he was annoyed that he couldn’t
look at the source code while looking at the help files of a function.
Also there was the added annoyance of having to jump back to the start
of the function to type ? back in AND deleting it once you’re done.
source("https://install-github.me/atusy/felp")
library(felp)
library(printr)
## From this:
?help()
## To this:
help?
## Alternatively:
felp(help)
felp("help")
## Source code is nicely highlighted by `prettycode`:
## Output shortened for brevity...
grep()?.
## function (pattern, x, ignore.case = FALSE, perl = FALSE, value = FALSE,
## fixed = FALSE, useBytes = FALSE, invert = FALSE)
## {
## if (!is.character(x))
## x <- structure(as.character(x), names = names(x))
## .Internal(grep(as.character(pattern), x, ignore.case, value,
## perl, fixed, useBytes, invert))
## }
## <bytecode: 0x000000001750ad50>
## <environment: namespace:base>
## Pattern Matching and Replacement
##
## Description:
##
## 'grep', 'grepl', 'regexpr', 'gregexpr' and 'regexec' search for
## matches to argument 'pattern' within each element of a character
## vector: they differ in the format of and amount of detail in the
## results.
##
## 'sub' and 'gsub' perform replacement of the first and all matches
## respectively.
##
## Usage:
##
## grep(pattern, x, ignore.case = FALSE, perl = FALSE, value = FALSE,
## fixed = FALSE, useBytes = FALSE, invert = FALSE)
##
## grepl(pattern, x, ignore.case = FALSE, perl = FALSE,
## fixed = FALSE, useBytes = FALSE)
##
## sub(pattern, replacement, x, ignore.case = FALSE, perl = FALSE,
## fixed = FALSE, useBytes = FALSE)
##
## gsub(pattern, replacement, x, ignore.case = FALSE, perl = FALSE,
## fixed = FALSE, useBytes = FALSE)
Short for f unctional h elp, he got this to work by modifying
the ? operator to show the inner structure of a function along with
the help page. This works for both a function as seen above and on
packages by package_name?p. You can also use the ? on data set
objects to return what you’ll normally get from a str() call in
addition the the help page.
iris?. ## also opens "Help" page for the dataset
## 'data.frame': 150 obs. of 5 variables:
## $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
## $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
## $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
## $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
## $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...
## Edgar Anderson's Iris Data
##
## Description:
##
## This famous (Fisher's or Anderson's) iris data set gives the
## measurements in centimeters of the variables sepal length and
## width and petal length and width, respectively, for 50 flowers
## from each of 3 species of iris. The species are _Iris setosa_,
## _versicolor_, and _virginica_.
##
## Usage:
##
## iris
## iris3
##
## Format:
##
## 'iris' is a data frame with 150 cases (rows) and 5 variables
## (columns) named 'Sepal.Length', 'Sepal.Width', 'Petal.Length',
## 'Petal.Width', and 'Species'.
##
## 'iris3' gives the same data arranged as a 3-dimensional array of
## size 50 by 4 by 3, as represented by S-PLUS. The first dimension
## gives the case number within the species subsample, the second the
## measurements with names 'Sepal L.', 'Sepal W.', 'Petal L.', and
## 'Petal W.', and the third the species.
##
## Source:
##
## Fisher, R. A. (1936) The use of multiple measurements in taxonomic
## problems. _Annals of Eugenics_, *7*, Part II, 179-188.
##
## The data were collected by Anderson, Edgar (1935). The irises of
## the Gaspe Peninsula, _Bulletin of the American Iris Society_,
## *59*, 2-5.
##
## References:
##
## Becker, R. A., Chambers, J. M. and Wilks, A. R. (1988) _The New S
## Language_. Wadsworth & Brooks/Cole. (has 'iris3' as 'iris'.)
##
## See Also:
##
## 'matplot' some examples of which use 'iris'.
##
## Examples:
##
## dni3 <- dimnames(iris3)
## ii <- data.frame(matrix(aperm(iris3, c(1,3,2)), ncol = 4,
## dimnames = list(NULL, sub(" L.",".Length",
## sub(" W.",".Width", dni3[[2]])))),
## Species = gl(3, 50, labels = sub("S", "s", sub("V", "v", dni3[[3]]))))
## all.equal(ii, iris) # TRUE
In the near future @Atsushi776 wants to get rid of not just the .
but the ? altogether and wants to work on using a prefix p? in front
of the package name to bring up the documentation for an entire package.
Go felp yourself by taking a look at the package
website!
0_u0: Marketing Science & R!
@0_u0 (better known as きぬいと or Kinuito) talked about his
successful attempt to integrate R into his workflow at the marketing
department of a very non-technical traditional Japanese company.
Most of the work being done for customers by his company is
descriptive statistics. Nothing fancy or A.I. or even simple linear
regression. As such, a lot of the problems that are given to his
department can be solved by tables and ggplots. As a consequence he
had been fighting an uphill battle as the company standard is to just
use Excel for … well literally everything.
Trying to find some way to incorporate R and Python to make his workflow
easier Kinuito started using the tidyverse to simplify the data
cleaning processes!

Key takeaways:
- Reduce overtime by using the
tidyverseto automate a lot of the grunt work involved with cleaning and transforming marketing data. - Not have to open up extraordinarily large Excel files (as much as before…).
- Great success in using
ggplot2andDiagrammeRfor creating informative output. - Start with descriptive statistics, you can’t do anything more advanced unless you have the infrastructure to do so!
Kinuito also highlighted some things he wanted to do in the near
future:
- Document R and Python tips for new graduate hires using R Markdown!
- Consolidate the company’s R environment:
- Currently version control is a mess as everybody is still only working in their own local environments.
- Solution: Docker?
Along with @kotaku08’s talk it was great to get more insight into how
R is used at various companies. I’ve personally only heard things from
an American or English company’s point of view (from the various R
conferences/meetups I’ve been to) so it was nice to hear about the
differences and similarities in the challenges faced by Japanese
corporations at this month’s TokyoR!
Other Talks
- don_du_maru: Levenshtein distance for remembering the name of the city that I live in!
- saltcooky: Statistical Network Analysis with R
- GotaMorishita: The origin of importance weight approach for covariate shift correction
- neronkai: Creating pdf documents with R
Food, Drinks, and Conclusion
Following all of the talks, those who were staying for the after-party
were served sushi and drinks! With a loud rendition of “kampai!”
(cheers!) R users from all over Tokyo began to talk about their
successes and struggles with R. A fun tradition at TokyoR is a
Rock-Paper-Scissors tournament with the prize being free data
science books!
The prize for this month was:
- Pandas for Everyone by Daniel Chen provided by Tom Kelly
TokyoR happens almost monthly and it’s a great way to mingle with
Japanese R users as it’s the largest regular meetup here in Japan. Talks
in English are also welcome so if you’re ever in Tokyo come join us!