I’ve lived in a couple of countries where talking (or more typically whinging) about the weather is a national past time so I took things one step further, by making a blog post about it!
The past few months we’ve had an absolute hell of a summer here in Tokyo. It wasn’t just hot, it was extremely humid too making things doubly worse! As some kinda coping mechanism I’ve been using R to create cool visualizations throughout the summer. This post will be a place where I can show all of them along with the code. I will also cover methods of getting Japanese weather data using the jmastats (Japan Meteorological Agency) and riem (ASOS airport weather stations) packages.
Let’s Begin!
library(jpndistrict) # install GitHub version to get English names in jpnprefs
library(sf) # spatial polygons
library(ggplot2) # plotting essentials
library(dplyr) # data wrangling
library(tidyr) # more data wrangling
library(purrr) # even more data wrangling
library(lubridate) # date wrangling
library(rvest) # webscraping
library(polite) # responsible webscraping
library(stringr) # string wrangling
library(riem) # airport weather station data
library(jmastats) # Japan Meteorological Agency data
library(ggrepel) # labels
library(gganimate) # animations
library(geofacet) # geographical facetting
library(gghighlight) # highlight stuff
# font packages
library(extrafont)
loadfonts(device = "win")
Tokyo Average Temperature Heat map (1876-2016)
Back in July, at the height of the summer heatwave, I came across this visualization by Toyo Keizai News on Twitter. Interestingly they provided a .json file of the data so I wanted to try recreating this in R!
On one hand, we could just use the jmastats package that I mentioned earlier to grab the data ourselves but since I had never dealt with .JSON data before I felt it was as good time as any to finally dive into it. Also, why go through the trouble if you already have the data sitting right there for you?
Let’s go through what we have to do. First, use the read_json() function from the jsonlite package to read in the data. Then, set the names for each vector with the year it corresponds to. Oddly some of the temperature values are factors so we need to change them into numeric. Then using another mapper function, we assign a new year variable to each of the “temperature per year” data frames with their respective years. Basically we’re bringing the year label we created for each list into an explicit value in the single (combined) data frame that we map as the output.
tokyo_his_temp <- jsonlite::read_json("../data/temperature.json", simplifyVector = TRUE)
tokyo_weather_df <- tokyo_his_temp %>%
set_names(nm = 1876:2018) %>%
map(~as.data.frame(.) %>%
modify_if(., is.factor, as.character) %>%
modify_if(., is.character, as.numeric)) %>%
map2_df(., names(.), ~ mutate(., year = .y)) %>%
rename(avg_temp = ".") %>%
mutate(year = as.numeric(year))
tokyo_weather_df %>% glimpse()
## Observations: 17,371
## Variables: 2
## $ avg_temp <dbl> 17.0, 19.1, 17.9, 18.8, 19.1, 20.8, 16.7, 18.7, 16.8,...
## $ year <dbl> 1876, 1876, 1876, 1876, 1876, 1876, 1876, 1876, 1876,...
Now we have a very lengthy data frame with the temperatures and their respective year. Now we have to add in the specific month-day pairs for each of the years. The heat map is going to be running from June 1st to September 30th, a span of 122 days. We can use the seq.Date() function to create a new variable of dates running from these two dates grouped by year.
tokyo_weather_df <- tokyo_weather_df %>%
filter(year != 2018) %>%
group_by(year) %>%
mutate(
date = seq.Date(from = as.Date("1876-06-01"),
by = "day",
length = 122),
date = format(date, "%m/%d")
) %>%
ungroup()
glimpse(tokyo_weather_df)
## Observations: 17,324
## Variables: 3
## $ avg_temp <dbl> 17.0, 19.1, 17.9, 18.8, 19.1, 20.8, 16.7, 18.7, 16.8,...
## $ year <dbl> 1876, 1876, 1876, 1876, 1876, 1876, 1876, 1876, 1876,...
## $ date <chr> "06/01", "06/02", "06/03", "06/04", "06/05", "06/06",...
Great! Now we have the data we need for plotting!
So, the point of this heat map visualization is to see the changes in temperature across time. We need to choose the right kind of color palette to emphasize the point we are trying to convey with this visualization. A great resource that I like to use is colorbrewer2.org where you can choose from a variety of classes and scales to fit your palette needs. The colors I chose came from the 8-class diverging palette, the website provides you with the Hex Code you need to pass into the appropriate scale_*() function. I also specify the breaks and labels for the color scale.
# colorbrewer2.org: diverging 8-class palette
cols <- rev(c('#d53e4f','#f46d43','#fdae61','#fee08b','#e6f598','#abdda4','#66c2a5','#3288bd'))
labels <- c("10", "12", "14", "16", "18", "20", "22", "24", "26", "28", "30", "32")
breaks <- c(seq(10, 32, by = 2))
The ggplot2 code I used was fairly straightforward. A nifty new package I started using lately is the glue package by Jim Hester, I used it here to format the text to appear in multiple lines in the plot (so I don’t have to use “” inside paste()). We’ll see more uses of this in my other visualizations later on!
tokyo_weather_df %>%
ggplot(aes(x = date, y = year, fill = avg_temp)) +
geom_tile() +
scale_fill_gradientn(
colours = cols,
labels = labels,
breaks = breaks,
limits = c(11.1, 33.2)) +
guides(fill = guide_colorbar(title = expression("Temperature " ( degree~C)),
reverse = FALSE,
title.position = "left",
label.position = "bottom",
nrow = 1)) +
scale_y_reverse(limits = c(2017, 1876), expand = c(0, 0),
breaks = c(1876, seq(1880, 2015, by = 10), 2017)) +
scale_x_discrete(breaks = c("06/01", "07/01", "08/01", "09/01", "09/30"),
labels = c("June 1st", "July 1st", "Aug. 1st",
"Sept. 1st", "Sept. 30th")) +
labs(title = "Summers in Tokyo are Getting Longer and Hotter (1876-2017)",
subtitle = glue::glue("
One Row = One Year, From June 1st to September 30th
Average Temperature (Celsius)
"),
caption = "Data from Toyo Keizai News via Japan Meteorological Agency") +
theme_minimal() +
theme(text = element_text(family = "Roboto Condensed", size = 12),
axis.title = element_blank(),
panel.grid = element_blank(),
legend.position = "bottom",
legend.key.width = unit(3, "cm"),
plot.margin=unit(c(1,1,1.5,1.2),"cm"))

Although Toyo Keizai stated that the data came from the Japan Meteorological Agency (I’ll mostly be referring to them as the JMA from here on out) and the measure is the average temperature for that day, I don’t know if the temperatures comes from the entirety of the Tokyo Prefecture (including the islands off the coast) or just from the 23 special wards that make up Tokyo City. It’s not necessarily a huge concern but it is something to consider.
For those that want to take a closer look I also created a Shiny app version of the above (here) so you can scroll around and look at the temperature for a specific day/year.
Tokyo Climate Stripes
Back in August I came across Ed Hawkins’ cool climate strip visualization, again on Twitter. There were several versions out for different countries and cities but I didn’t see Tokyo on there, so thinking it’ll be a good opportunity for some practice I went ahead and tried to recreate it!
This time I’m getting data straight from the JMA, the “annual temperature table” from this link here.
url <- "http://www.data.jma.go.jp/obd/stats/etrn/view/annually_s.php?prec_no=44&block_no=47662"
session_jma <- url %>%
read_html() %>%
html_nodes("#tablefix1") %>%
.[[1]] %>%
html_table(fill = TRUE, header = FALSE)
Welp. What a giant mess of a table! Thankfully our trust dplyr verbs and regex can solve our problems. Et Voilà!
tokyo_year_avg_temp <- session_jma %>%
select(year = X1, avg_temp = X8, avg_high = X9, avg_low = X10,
high_temp = X11, low_temp = X12) %>%
slice(-c(1, 2, 3)) %>%
mutate(avg_temp = avg_temp %>% str_remove("\\]") %>% as.numeric(),
avg_high = avg_high %>% str_remove("\\]") %>% as.numeric(),
avg_low = avg_low %>% str_remove("\\]") %>% as.numeric(),
high_temp = high_temp %>% str_remove("\\]") %>% as.numeric(),
low_temp = low_temp %>% str_remove("\\]") %>% as.numeric(),
year = forcats::as_factor(year))
tokyo_year_avg_temp %>% glimpse()
## Observations: 144
## Variables: 6
## $ year <fct> 1875, 1876, 1877, 1878, 1879, 1880, 1881, 1882, 1883...
## $ avg_temp <dbl> 17.0, 13.6, 14.2, 13.8, 14.6, 14.1, 13.8, 14.0, 13.3...
## $ avg_high <dbl> 21.9, 18.7, 19.1, 18.3, 19.4, 19.2, 18.8, 18.6, 17.8...
## $ avg_low <dbl> 12.2, 8.3, 8.9, 9.6, 10.0, 9.1, 8.5, 9.0, 9.1, 8.6, ...
## $ high_temp <dbl> 35.1, 35.6, 34.9, 35.1, 33.9, 33.2, 34.2, 34.2, 32.8...
## $ low_temp <dbl> -3.6, -9.2, -4.8, -7.6, -5.5, -6.8, -8.4, -6.3, -7.8...
I was wondering what kind of color palette Ed used… so going back to the Twitter thread I saw somebody opine that he might have used the “10-class divergent RD-BU” from colorbrewer2.org. I checked it out and it seemed very similar so I went ahead with that!
# 10 Class Divergent Rd-Bu: http://colorbrewer2.org/#type=diverging&scheme=RdBu&n=10
temp_cols <- rev(c('#67001f','#b2182b','#d6604d','#f4a582','#fddbc7',
'#d1e5f0','#92c5de','#4393c3','#2166ac','#053061'))
The plot was very simple. I used geom_bar() for the stripes and specified width = 1 so that the bars left no gap in between each other. Then I erased all the axes and labels with theme_void().
tokyo_year_avg_temp %>%
# filter out 1875 and 2018 due to uncertainties in the measurements
# http://www.data.jma.go.jp/obd/stats/data/mdrr/man/remark.html
filter(!year %in% c(1875, 2018)) %>%
ggplot(aes(x = year, fill = avg_temp)) +
geom_bar(position = "fill", width = 1) +
scale_y_continuous(expand = c(0, 0.01)) +
scale_x_discrete(expand = c(0, 0)) +
scale_fill_gradientn(colors = temp_cols, "Average Temperature (Celsius)") +
labs(title = "Tokyo: Annual Average Temperature (1876-2017)",
subtitle = "One Stripe = One Year, Left: 1876, Right: 2017") +
theme_void() +
theme(text = element_text(family = "Roboto Condensed"),
legend.position = "bottom",
legend.title = element_text(family = "Roboto Condensed"))
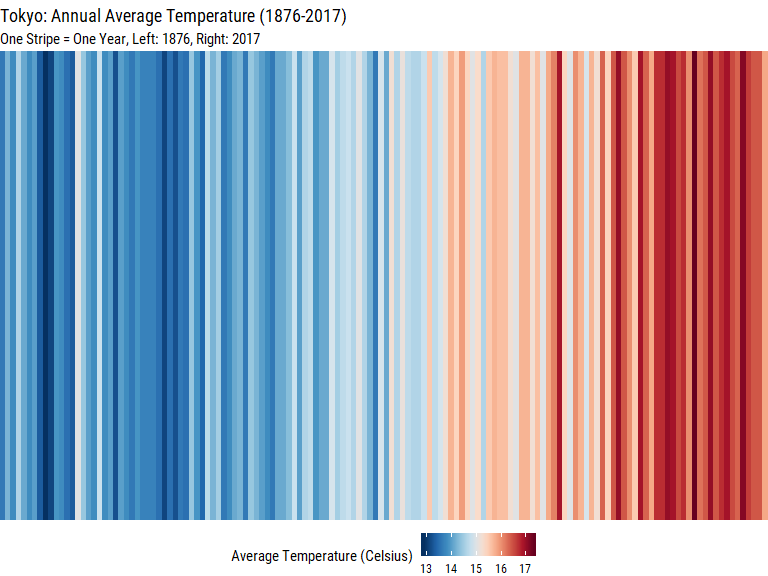
Very minimal yet very effective at showing the shift in temperature over time!
Gathering Japanese Weather Data ft. riem & jmastats
The two places I know where to get Japan weather data using R is via riem and jmastats. In this section I’ll go through what you need to do to get the data from both of these packages.
riem
The riem package is a ROpenSci project authored by Maëlle Salmon that lets you download airport weather data from the Iowa Environmental Mesonet website. You can search for airport networks from all over the world and because the Japan ASOS weather stations take measurements at 30 minute intervals, you can get A LOT of data!
I found about this package last year through a #rstats mini event on Twitter (started off here) where people started to create XKCD-themed charts showing the most comfortable (weather-wise) place to live. I even made a blog post last year showing a version of this chart for Japan!
In the example below I’ll just be using the same set of Japanese airports I used back then, the top 50 busiest airports in Japan. I feel like it’s a fair representation across the prefectures and although I could use the “list of airports in Japan” wiki page that has a lot of small airports and military base airports that wouldn’t really be appropriate.
A few minor changes were necessary however as oddly I can’t seem to get the data from any of the Nagoya airports through this package nor the API on the Iowa Environmental Mesonet website…they used to work when I did the XKCD blog post a year ago but whatever, we’ll skip over those for now. We’ll just use RJGG which is the Chubu Centrair Int’l Airport as it’s the official Nagoya (and the Chubu region’s) international airport nowadays anyways…
# web scrape busiest Japan airport codes
session <- bow("https://en.wikipedia.org/wiki/List_of_the_busiest_airports_in_Japan")
japan_airports <- scrape(session) %>%
html_nodes("table.wikitable:nth-child(8)") %>%
.[[1]] %>%
html_table()
japan_airports_clean <- japan_airports %>%
janitor::clean_names() %>%
mutate(city = cityserved %>% iconv(from = "UTF-8", to = "ASCII//TRANSLIT")) %>%
select(airport, city, iata_icao) %>%
separate(iata_icao, c("IATA", "ICAO"), "\\/") %>%
mutate(city = case_when(
ICAO == "RJAH" ~ "Ibaraki", # fix Ibaraki Airport listed as Tokyo
ICAO == "RJOK" ~ "Kochi", # fix Kochi, Kochi to Kochi
TRUE ~ city
)) %>%
# filter out Narita and Kansai Airports
# filter out RJNA (Nagoya) as not working for some reason
# RJGG is also Nagoya so I'll use that instead
filter(!ICAO %in% c("RJAA", "RJBB", "RJNA"))
Now that we have the ICAO codes for the Japanese airports we want, we can pass these codes into the riem_measures() function along with the date range. We use a mapper function map_df() as we want to iterate over all the airport codes in one go.
# grab weather data from stations
summer_weather_riem_raw <-
map_df(japan_airports_clean$ICAO, riem_measures,
date_start = "2018-06-01",
date_end = "2018-08-31")
Great! Now we can do a bit of cleaning and also calculate the daily averages for a few temperature related measures as what riem_measures() gives us is a bit too granular for our purposes. Then, combine it back with the airport metadata.
# calculate daily averages
sum_air <- summer_weather_riem_raw %>%
mutate(time = as_date(valid) %>% ymd()) %>%
separate(time, into = c("year", "month", "day"), sep = "-") %>%
group_by(month, day, station) %>%
summarize(avg_temp = mean(tmpf),
max_temp = max(tmpf),
min_temp = min(tmpf),
avg_dewp = mean(dwpf)) %>%
ungroup() %>%
# join riem data with airport data
left_join(japan_airports_clean, by = c("station" = "ICAO")) %>%
glimpse()
## Observations: 4,172
## Variables: 10
## $ month <chr> "06", "06", "06", "06", "06", "06", "06", "06", "06",...
## $ day <chr> "01", "01", "01", "01", "01", "01", "01", "01", "01",...
## $ station <chr> "RJAH", "RJBE", "RJCB", "RJCC", "RJCH", "RJCK", "RJCM...
## $ avg_temp <dbl> 66.60645, 69.80000, 55.40000, 57.82449, 59.69231, 57....
## $ max_temp <dbl> 75.2, 73.4, 59.0, 69.8, 64.4, 64.4, 57.2, 73.4, 75.2,...
## $ min_temp <dbl> 59.0, 64.4, 50.0, 51.8, 55.4, 50.0, 44.6, 64.4, 68.0,...
## $ avg_dewp <dbl> 56.96774, 57.68000, 48.07143, 50.62449, 56.23077, 43....
## $ airport <chr> "Ibaraki Airport", "Kobe Airport", "Obihiro Airport",...
## $ city <chr> "Ibaraki", "Kobe", "Obihiro", "Sapporo", "Hakodate", ...
## $ IATA <chr> "IBR", "UKB", "OBO", "CTS", "HKD", "KUH", "MMB", "UBJ...
With that done we can play around with the data a bit like changing from Fahrenheit to Celsius with the help of the weathermetrics package.
library(weathermetrics)
# convert from Fahrenheit to Celsius!
sum_air %>%
mutate_at(vars(contains("temp")),
~convert_temperature(temperature = ., old_metric = "f", new_metric = "c")) %>%
select(contains("temp")) %>%
glimpse()
## Observations: 4,172
## Variables: 3
## $ avg_temp <dbl> 19.23, 21.00, 13.00, 14.35, 15.38, 14.20, 11.71, 21.5...
## $ max_temp <dbl> 24, 23, 15, 21, 18, 18, 14, 23, 24, 20, 26, 26, 24, 2...
## $ min_temp <dbl> 15, 18, 10, 11, 13, 10, 7, 18, 20, 13, 17, 14, 16, 18...
You can also calculate the humidex (index of comfort combining temperature and humidity) with the comf package:
library(comf)
sum_air %>%
mutate_at(vars(contains("avg")),
~convert_temperature(temperature = ., old_metric = "f", new_metric = "c")) %>%
mutate(humidex = calcHumx(ta = avg_temp, rh = relh)) %>%
select(month, day, station, airport, humidex) %>%
slice(1:5)
## # A tibble: 5 x 5
## month day station airport humidex
## <chr> <chr> <chr> <chr> <dbl>
## 1 06 01 RJAH Ibaraki Airport 15.4
## 2 06 01 RJBE Kobe Airport 17.4
## 3 06 01 RJCB Obihiro Airport 8.22
## 4 06 01 RJCC New Chitose Airport 9.76
## 5 06 01 RJCH Hakodate Airport 11.2
I took out a lot of the other weather variables like wind direction, wind speed, visibility, pressure altimeter, etc. that you can get from riem as I was only interested in the temperature stuff but you can see what each of the variables are from the documentation or you can go directly to the Iowa Environmental Mesonet website to find more details!
jmastats
In the visualizations I made in the first section, I used data from the JMA but it was either indirectly or through web scraping. So now I’ll show you a way to get data directly using R with the jmastats package! This useful package is authored by Shinya Uryu and it is still in the early stages of its development. Through a variety of presentations and gists (Ex. 1, 2) he has demonstrated some of the cool things you can do with it, even if you can’t read Japanese I suggest you check it out for the visualizations!
First, let’s create a small map of the JMA weather stations in Tokyo to give us a little context about the Japan Meteorological Agency and its weather stations. We can use the weather stations metadata from the jmastats package and filter for stations located in Tokyo Prefecture to create our map.
The Automated Meteorological Data Acquisition System (AMeDAS) is the 1,300 station network spread throughout Japan that uses automatic observation equipment to measure and record data such as the weather, wind direction/speed, precipitation, humidity and more. There are both manned and unmanned stations which send data back to the JMA Headquarters at 10 second or 10 minutes intervals depending on the type of data.
Here’s a picture of one of these AMeDAS installations:

I’ll also include the regional weather headquarters in Tokyo for this map (this station doesn’t use AMeDAS). Below I pull out the latitude and longitude coordinates from the geometry column of the stations data set.
tky_stations_raw <- jmastats::stations %>%
filter(area == "東京" & address != "千代田区北の丸公園")
tky_stations <- tky_stations_raw %>%
mutate(
centroid = map(geometry, st_centroid),
coords = map(centroid, st_coordinates),
coord_x = map_dbl(coords, 1),
coord_y = map_dbl(coords, 2)) %>%
select(-centroid, - coords)
Using the jpn_pref() function from the jpndistrict package we specify the spatial polygons data we want to grab. In the pref_code argument we pass 13 as that’s the prefectural code for the Tokyo Prefecture. Then I try to filter out the Ogasawara Islands as they are way off the coast of Japan. There’s still some other islands but since they are part of districts on the mainland you can’t just filter them out like we did with the Ogasawara Islands. Therefore I’m going to use the “hacksaw” approach and just cut them out from our view by specifying the x and y limits (the coordinates).
For the plot we’ll use fontawesome to represent the weather stations with cool icons. There’s no “weather station” icon so I just used something that looks like a building.
library(emojifont)
load.fontawesome()
sf_pref13 <- jpn_pref(pref_code = 13) %>%
st_simplify(dTolerance = 0.001) %>%
mutate(city_code = as.numeric(city_code)) %>%
filter(city_code != 13421) %>% # filter out the Ogasawara Islands (waaayy off the coast)
st_union()
# fix "holes" from st_union(): https://uribo.hatenablog.com/entry/2018/08/14/000541
sf_pref13_FIX <- sf_pref13 %>%
st_cast("POLYGON") %>%
map(~ .x[1]) %>%
st_multipolygon() %>%
st_sfc(crs = 4326) %>%
as.data.frame() %>%
mutate(jis_code = "13", prefecture = "Tokyo") %>%
magrittr::set_names(c("geometry", "jis_code", "prefecture")) %>%
st_as_sf()
# Insert fontawesome icon into a 'label' column
tky_stations <- tky_stations %>%
filter(coord_y > 35) %>%
mutate(label = fontawesome(c("fa-university")))
sf_pref13 %>%
ggplot() +
geom_sf(fill = "white") +
coord_sf(xlim = c(138.9, 139.95),
ylim = c(35.47, 35.9)) +
geom_label(data = tky_stations,
aes(x = coord_x, y = coord_y,
label = label),
family = "fontawesome-webfont") +
geom_label_repel(data = tky_stations,
aes(x = coord_x, y = coord_y,
label = station_name),
size = 3, nudge_y = -0.025) +
theme_minimal() +
theme(axis.title = element_blank(),
axis.ticks = element_blank())
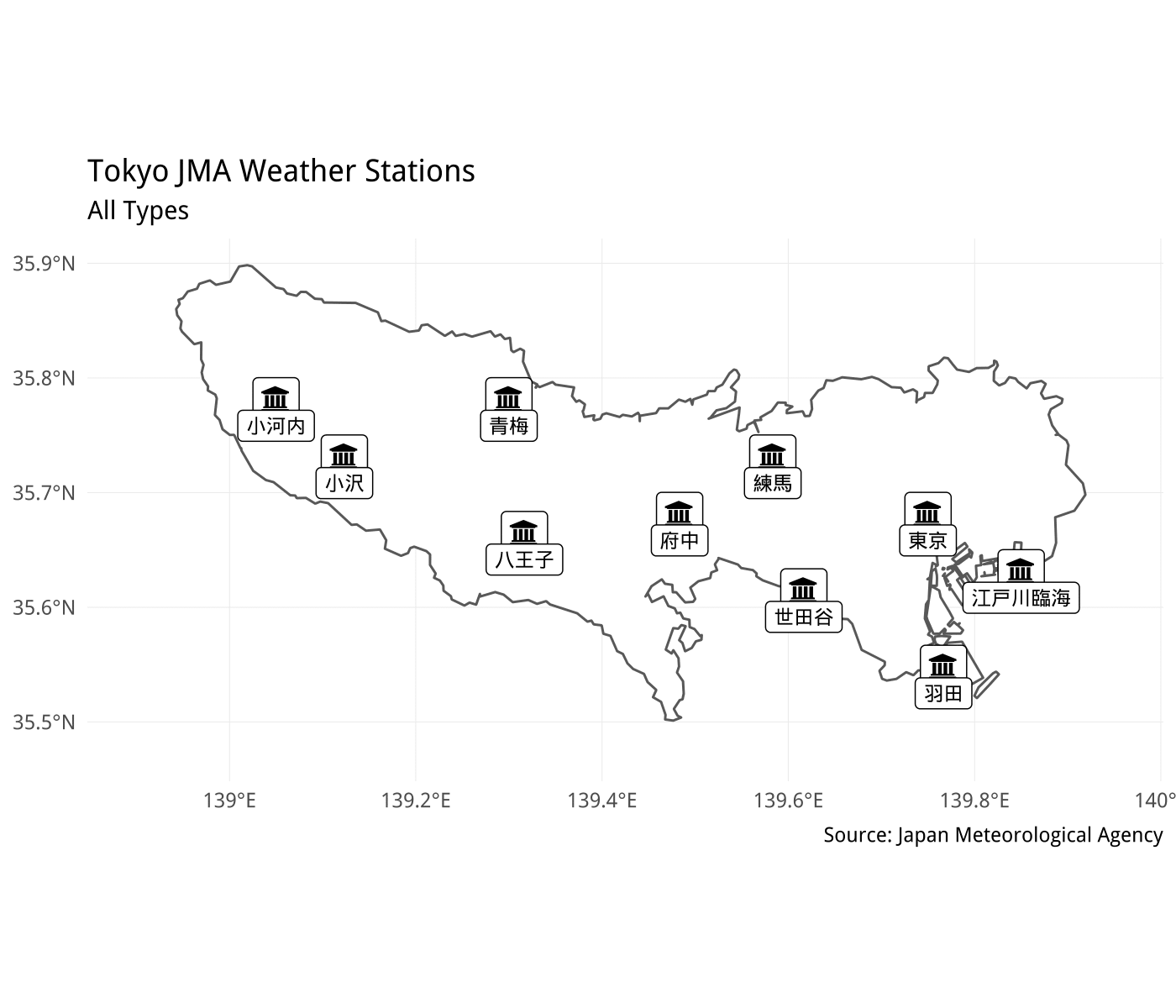
You can see that the weather stations in Tokyo Prefecture are pretty well spread throughout the area. I’ll go over the differences between the station types a bit later.
Now that we got a little bit of context we can move on to the fun part!
Let’s focus on grabbing weather data from largely populated areas. So what we can do is to grab coordinates for each of prefecture capitals from the jpndistrict::jpnprefs data set, then pass those coordinates into the jmastats::nearest_station() function to find the closest stations based on the capital city coordinates. Finally, we use the jma_collect() function to grab weather data for those stations.
jpnprefs <- jpndistrict::jpnprefs
lat <- jpnprefs %>% select(capital_latitude) %>% as_vector()
lon <- jpnprefs %>% select(capital_longitude) %>% as_vector()
japan_stations_coords <- map2(
lon, lat,
~ nearest_station(longitude = .x, latitude = .y,
geometry = NULL))
j_stat_ref <- japan_stations_coords %>%
map(~as.data.frame(.)) %>%
reduce(rbind)
Interestingly, the nearest_stations() function gives us a new column in our data frame showing how far away the station is from the coordinates we supplied it with. Let’s take a look at the average distance of each station from each prefecture capital!
j_stat_ref %>%
summarize(avg_distance = mean(distance) %>% units::set_units(km))
## avg_distance
## 1 2.199498 km
So on average the stations were ~2.2 km away from the prefecture capital coordinates we gave the nearest_stations() function, looks good to me!
j_station_df <- j_stat_ref %>%
select(-geometry) %>%
left_join(jmastats::stations %>% st_set_geometry(NULL),
by = c("station_no", "area", "station_name")) %>%
# erase duplicate stations from the joining
distinct(station_name, .keep_all = TRUE)
We now have one station per prefecture that is as close to each capital city as possible!
Now we can use the jma_collect() function to get data from each station for each of the summer months (June, July, and August).
month <- c(6, 7, 8) # June, July, August
block_no <- j_station_df %>% select(block_no) %>% as_vector()
# create a dataframe consisting of every combination of month and station
df <- crossing(block_no, month)
# jma_collect()
j_sum_weather_raw <- map2(.x = df$block_no, .y = df$month,
~ jma_collect(item = "daily", block_no = .x, year = 2018, month = .y) %>%
mutate(block = .x))
# bind rows and select only the columns necessary
j_all_weather_df <- j_sum_weather_raw %>%
bind_rows() %>%
select(1, 17, 5, 6, 7) %>%
magrittr::set_colnames(c("date", "block",
"temperature_average", "temperature_max", "temperature_min"))
# stations metadata
stations_df <- jmastats::stations %>%
select(pref_code, block_no, station_name, station_no, area) %>%
st_set_geometry(NULL) # no need for the station coordinate data now
# combine to get prefecture codes for each station
j_temp_stations_df <- j_all_weather_df %>%
left_join(stations_df, by = c("block" = "block_no")) %>%
# some stations have same coordinates for 2 station types...
distinct(block, date, .keep_all = TRUE) %>%
mutate(pref_code = as.numeric(pref_code)) %>%
left_join(jpnprefs %>% mutate(jis_code = as.numeric(jis_code)),
by = c("pref_code" = "jis_code")) %>%
select(-contains("capital_l"))
So now we have a large data frame of weather data for one station per prefecture from June to September!
We can also add in spatial polygons data (from the jpndistrict package) to create maps:
# Japan spatial polygons from jpndistrict package
sf_ja <- 1:47 %>% # Prefectural codes 1-47
map(~jpndistrict::jpn_pref(pref_code = ., district = FALSE)) %>%
reduce(rbind) %>%
st_simplify(dTolerance = 0.01) %>%
mutate(pref_code = as.numeric(pref_code))
# combine temp with spatial df
j_temp_map_stations_df <- j_temp_stations_df %>%
mutate(pref_code = as.numeric(pref_code)) %>%
left_join(sf_ja, by = c("pref_code", "prefecture"))
The jma_collect() function gives us a lot of variables but depending on the station type some of these may not be filled in. I include a table below in English for the types of weather stations and the type of weather variables they record and in the GitHub repo I include a station metadata file from the JMA (in Japanese).
| Station Type | Observed Measurements |
|---|---|
| 四 | precipitation (in mm.), temperature, wind direction, wind speed, hours of sunlight |
| 三 | precipitation (in mm.), temperature, wind direction, wind speed |
| 官 | precipitation (in mm.), temperature, wind direction, wind speed, hours of sunlight (only certain stations), snowfall/depth (only certain stations) |
| 雨 | precipitation (in mm.) |
| 雪 | snowfall/depth (in cm.) |
For the purposes of this blog post I only wanted temperature data, which is something nearly all station types collect, so we are good to go! For those of you seeking other types weather data it is important that you carefully read the documentation provided by the JMA.
To conclude, there’s definitely a lot more steps compared to the riem package but on the other hand we are not limited to taking data only from weather stations at airports!
Plotting Weather Data
Now that we’ve got our data, let’s make some plots! How about we take a look at the prefectures with the highest average temperatures throughout the summer months?
If we use geom_line() to check out how each of the prefectures stack up, it’s really hard to interpret as there are so many lines! We could just filter() for the top 5 or use top_n() but then we lose context as we can’t see those lines in relation to all the other prefectures. The solution here is the gghighlight package made by Hiroaki Yutani.
With the gghighlight() function we can specify the filtering variable as the average of the average temperatures with mean(temperature_average). Then with the max_highlight argument we can define the maximum number of the top prefectures we want highlighted, I’ll go with the top 5 here. (Small reminder that I am using each of the capital city’s temperatures to represent each of the prefectures!)
cols <- c("Okinawa" = "#e41a1c", "Saga" = "#377eb8",
"Kagoshima" = "#4daf4a", "Kumamoto" = "#984ea3",
"Gifu" = "#ff7f00")
j_temp_colors <- j_temp_stations_df %>%
# remove the prefecture suffixes from the english names
mutate(prefecture_en = str_replace(prefecture_en, "\\-.*", ""))
j_temp_colors %>%
ggplot() +
geom_line(aes(x = date, y = temperature_average,
color = forcats::fct_reorder(prefecture_en, temperature_average,
.fun = mean, .desc = TRUE)),
size = 0.75) +
scale_color_manual(name = "Top 5 Prefectures", values = cols) +
gghighlight(mean(temperature_average), max_highlight = 5,
use_direct_label = FALSE) +
scale_x_date(labels = c("June 1st", "July 1st", "August 1st", "August 31st"),
breaks = as.Date(c("2018-06-01", "2018-07-01", "2018-08-01", "2018-08-31")),
expand = c(0, 0)) +
scale_y_continuous(breaks = scales::pretty_breaks(n = 5),
expand = c(0, 0)) +
labs(title = "Top 5 Prefectures with Highest Average Temperature",
subtitle = "Averaged over the Summer Months (June 1st - August 31st)",
caption = "Source: Japan Meteorological Agency",
y = "Average Temperature (°C)") +
theme_minimal() +
theme(axis.title.x = element_blank(),
text = element_text("Roboto Condensed"))
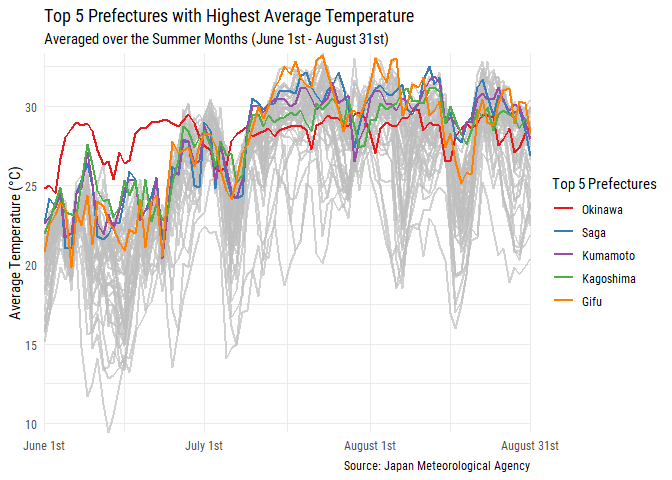
No surprises here with the top 5 consisting of prefectures in the south except for Gifu! With this plot you can clearly see how Okinawa is much hotter compared to the rest of Japan in June and then in July you see the other prefectures “catching up” in a sense. Okinawa doesn’t have the highest daily average temperatures but compared to other prefectures it is consistently hot and this is why it’s in first place.
We can also compare prefectures in each region against each other. Let’s nest prefectures by their regions using group_by() and nest(). Then, we can make a plot for each of these nested regions comparing the prefecture’s average temperature to the region’s average temperature on… let’s just say the day of the summer solstice, this year it was on the 21st of June!
region_plots <- j_temp_colors %>%
filter(date == "2018-06-21") %>% # day of the summer solstice
group_by(region_en) %>%
mutate(region_avg_temp = mean(temperature_average) %>% round(digits = 2)) %>%
nest() %>%
mutate(plot = map2(.x = region_en, .y = data,
~ ggplot(data = .y,
aes(
x = forcats::fct_reorder(prefecture_en, temperature_average,
.desc = TRUE),
y = temperature_average
)) +
geom_segment(aes(y = region_avg_temp, yend = temperature_average,
xend = prefecture_en),
color = "skyblue",
size = 1.5) +
geom_point(color = "red",
size = 2.5,
show.legend = FALSE) +
geom_hline(aes(yintercept = region_avg_temp)) +
scale_x_discrete(expand = c(0.01, 0.01)) +
scale_y_continuous(breaks = scales::pretty_breaks(n = 5)) +
labs(title = glue::glue(
"{.x} Region"),
subtitle = glue::glue(
"Average Regional Temperature ({.y$region_avg_temp} °C)"),
x = NULL,
y = "Temperature (°C)") +
theme_minimal() +
theme(text = element_text(family = "Roboto Condensed", size = 7),
axis.text.x = element_text(size = 8.5),
panel.grid.major.x = element_blank(),
panel.grid.minor.y = element_blank()))
)
glimpse(region_plots)
## Observations: 8
## Variables: 3
## $ region_en <chr> "Kanto", "Kansai", "Hokkaido", "Tohoku", "Chubu", "C...
## $ data <list> [<# A tibble: 7 x 17, date block temperatur...
## $ plot <list> [<17703, 17703, 17703, 17703, 17703, 17703, 17703, ...
# show ALL 8 plots at once:
# walk(region_plots$plot, print)
I could use walk() to show all the plots at once but it’s a bit messy, so let’s use the patchwork package by Thomas Pedersen instead!
kanto <- region_plots$plot[[1]]
kansai <- region_plots$plot[[2]]
hokkaido <- region_plots$plot[[3]]
tohoku <- region_plots$plot[[4]]
chubu <- region_plots$plot[[5]]
chugoku <- region_plots$plot[[6]]
kyushu <- region_plots$plot[[7]]
shikoku <- region_plots$plot[[8]]
library(patchwork)
# group them up, going top = north, bottom = south
(hokkaido + tohoku) / (chubu + kanto) / (kansai + chugoku) / (shikoku + kyushu) +
plot_annotation(title = "Regional Temperatures on the Summer Solstice (June 21st, 2018)",
subtitle = "Horizontal line: Average Regional Temperature",
caption = "Source: Japan Meteorological Agency")
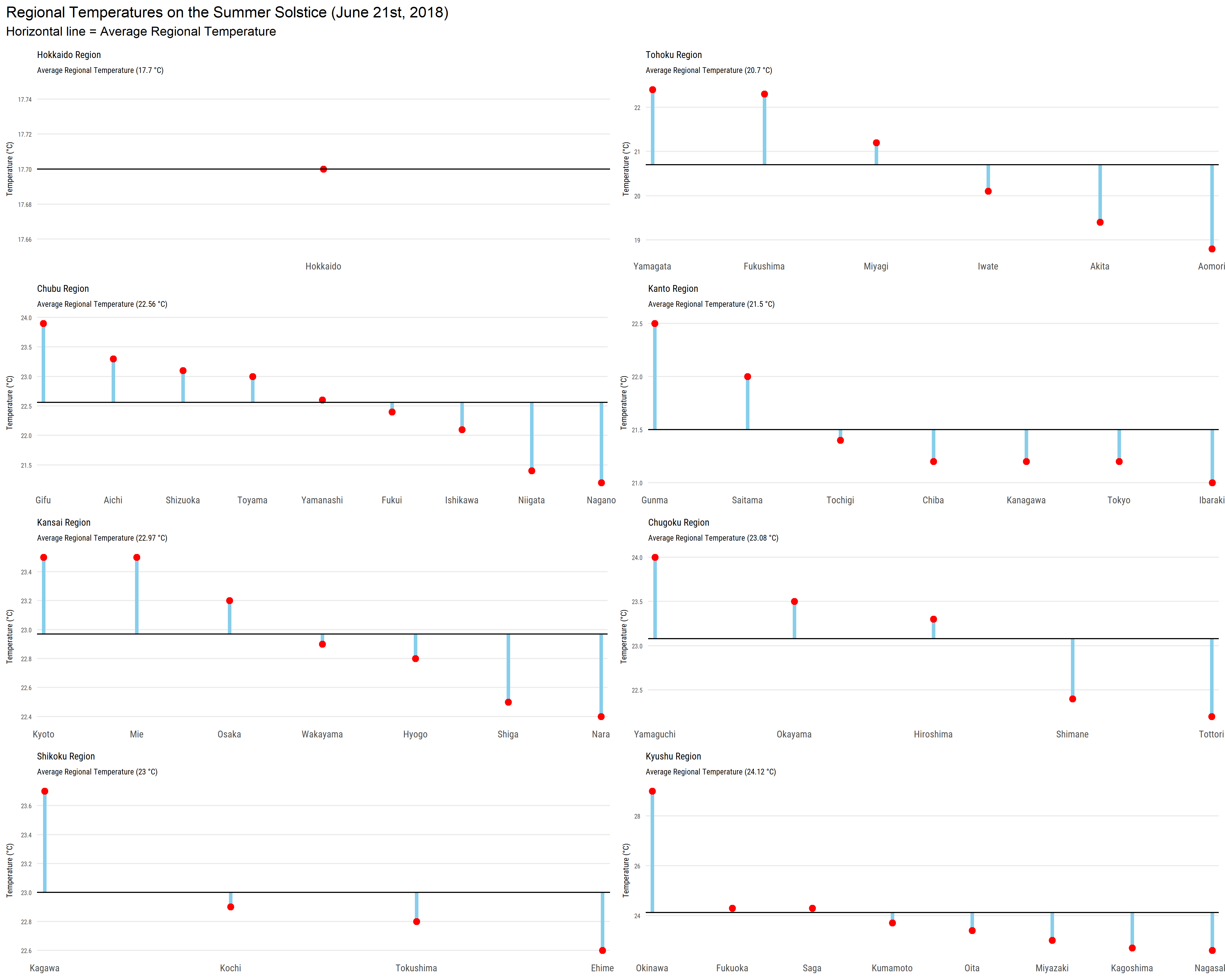
These prefectures are divided into the official regional divisions of Japan. Although they are not official administrative units in any shape or form, things like weather reports use these regions to report the weather. We can see that with Okinawa being part of the Kyushu region it drastically skews the average while Hokkaido is the only prefecture in its region. For a deeper analysis it might be prudent to divide the prefectures a bit differently!
We can look at bar graphs and other usual types of visualizations but for those not familiar with Japanese prefectures the results may not be obvious, unique, or wouldn’t provide much of a geographical context to the data. In the above plots you had to just trust what I was saying about the prefectures to be true. So let’s try plotting the data on top of a map of japan!
I’ll use gganimate to cycle through each of the days in the summer months. The jmastats package also comes with some very nice color/fill palettes for both relative and absolute scales, you can access them by calling jmastats:::jma_pal().
j_temp_map_stations_df %>%
ggplot() +
geom_sf(aes(fill = temperature_average)) +
scale_fill_gradientn(colours = jmastats:::jma_pal(
palette = "relative", .attribute = FALSE)[6:1],
labels = c("35", "30", "25",
"20", "15", "10"),
breaks = c(35, 30, 25, 20, 15, 10),
limits = c(9, 35.5),
name = glue::glue(
"Temperature (°C)")) +
scale_x_continuous(expand = c(0, 0)) +
scale_y_continuous(expand = c(0, 0)) +
labs(
title = "Average Daily Temperature (°C) in Japan",
subtitle = "{frame_time}",
caption = "Source: Japan Meteorological Agency",
x = NULL, y = NULL) +
theme_minimal() +
theme(
text = element_text(family = "Roboto Condensed"),
legend.position = c(0.8, 0.3),
legend.background = element_rect(color = "black"),
legend.title = element_text(size = 10),
axis.title = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
plot.margin = unit(c(1, 0, 0, 0), "mm")) +
# animate on date
transition_time(date, range = as.Date(c("2018-06-01", "2018-08-31")))
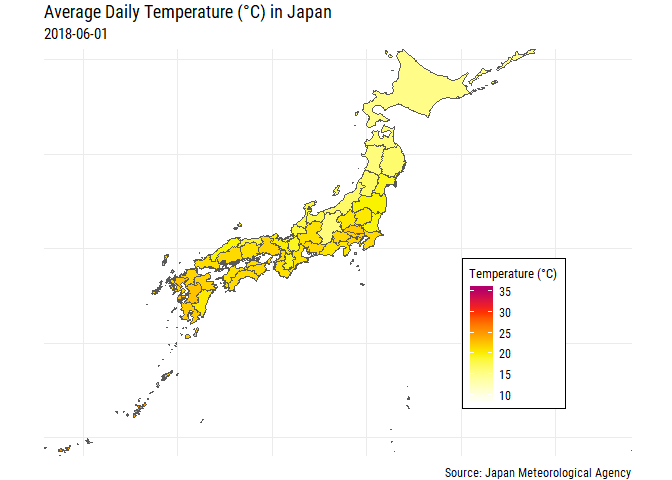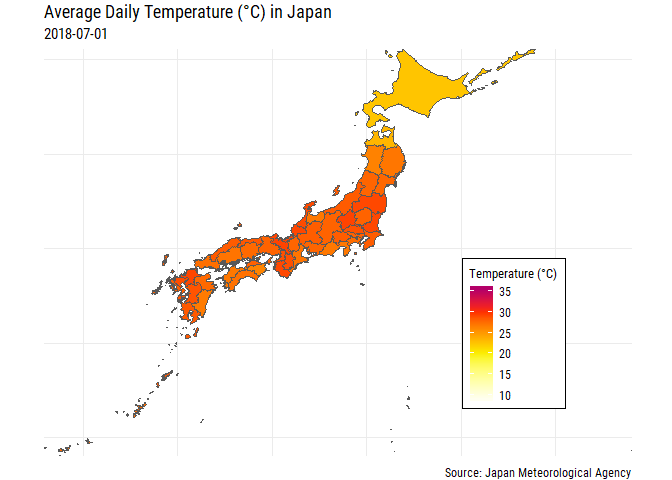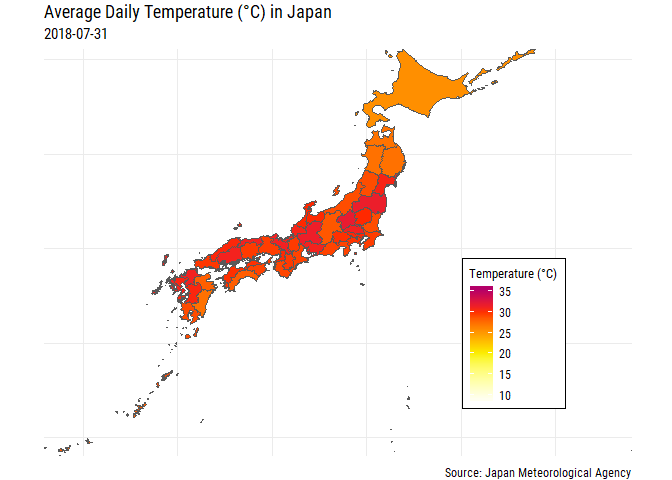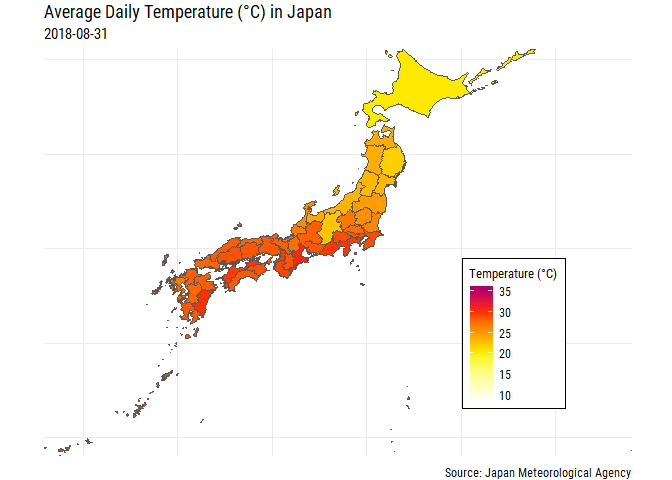
OK that gives us a bit more context, at least geographically! But for those of us that don’t know which prefectures are which we’re right back to where we started unless we label each of the prefectures! Also, some parts of Japan are pretty small and we can’t really see the filled color too well, especially Tokyo and Okinawa.
What can we do to solve this problem?
There are a variety of options with/without R including cartograms, hex tile maps, choropleth maps, etc… or we could try using geofacets!
The package author, Ryan Hafen, gives a great overview on the advantages and disadvantages of geofacetting compared to other methods here but to summarize:
- each geographic facet can present more than a singular value
- each geographic facet can contain any kind of
ggplot2plot - each geographic facet is provided the same amount of space
Let’s try it out!
The main function to note here is the facet_geo() function which allows you to specify how the facets are laid out geometrically. There are currently 64 grids from all over the world available in the package and you specify them using the grid argument. Like before I’ll also set up the colors for each region and plot. The use_direct_label argument in gghighlight() is used to specify whether you want the labels added on the plot (TRUE) or in the legend (FALSE).
(10/23/18 NOTE: I made a PR to fix the positioning of the Tochigi, Gunma, and Ibaraki prefectures in the geofacets grid a few weeks back but I still haven’t gotten back a response so I’ll just change it by hand below. Thanks to Tom for originally pointing this out on Twitter!)
# Fix issue of grid dataframe not recognizing the facetted variable name:
pref_names <- j_temp_map_stations_df %>%
mutate(prefecture_en = str_replace(prefecture_en, "\\-.*", "")) %>%
distinct(pref_code, prefecture_en) %>%
arrange(pref_code) %>%
magrittr::use_series(prefecture_en)
jp_prefs_grid1 <- jp_prefs_grid1 %>%
arrange(code_pref_jis) %>%
# fix Tochigi, Gunma & Ibaraki positioning:
mutate(col = as.numeric(case_when(
code == "9" ~ "13",
code == "8" ~ "14",
code == "10" ~ "12",
TRUE ~ as.character(col))),
row = as.numeric(case_when(
code == "9" ~ "5",
code == "8" ~ "6",
TRUE ~ as.character(row)))) %>%
mutate(prefecture_en = pref_names)
# colors by region
cols <- c("Kyushu" = "#e41a1c", "Shikoku" = "#377eb8", "Chugoku" = "#4daf4a", "Chubu" = "#984ea3",
"Kansai" = "#ff7f00", "Kanto" = "#ffff33", "Tohoku" = "#a65628", "Hokkaido" = "#f781bf")
# plot!
j_temp_colors %>%
ggplot(aes(date, temperature_average)) +
geom_line(aes(color = region_en), size = 0.75, show.legend = FALSE) +
scale_color_manual(values = cols) +
scale_y_continuous(breaks = c(10, 20, 30)) +
gghighlight(use_direct_label = FALSE) +
labs(title = glue::glue("Average Daily Temperature (°C) in Japan"),
subtitle = "June ~ August 2018, Colored by Region",
caption = "Source: Japan Meteorological Agency") +
theme_minimal() +
theme(text = element_text(family = "Roboto Condensed"),
title = element_text(size = 18),
axis.title = element_blank(),
panel.grid.minor.x = element_blank(),
strip.background = element_rect(color = "black", linetype = "solid"),
strip.text.x = element_text(size = 10.5),
axis.text = element_text(size = 8)) +
facet_geo(~ prefecture_en,
grid = "jp_prefs_grid1")
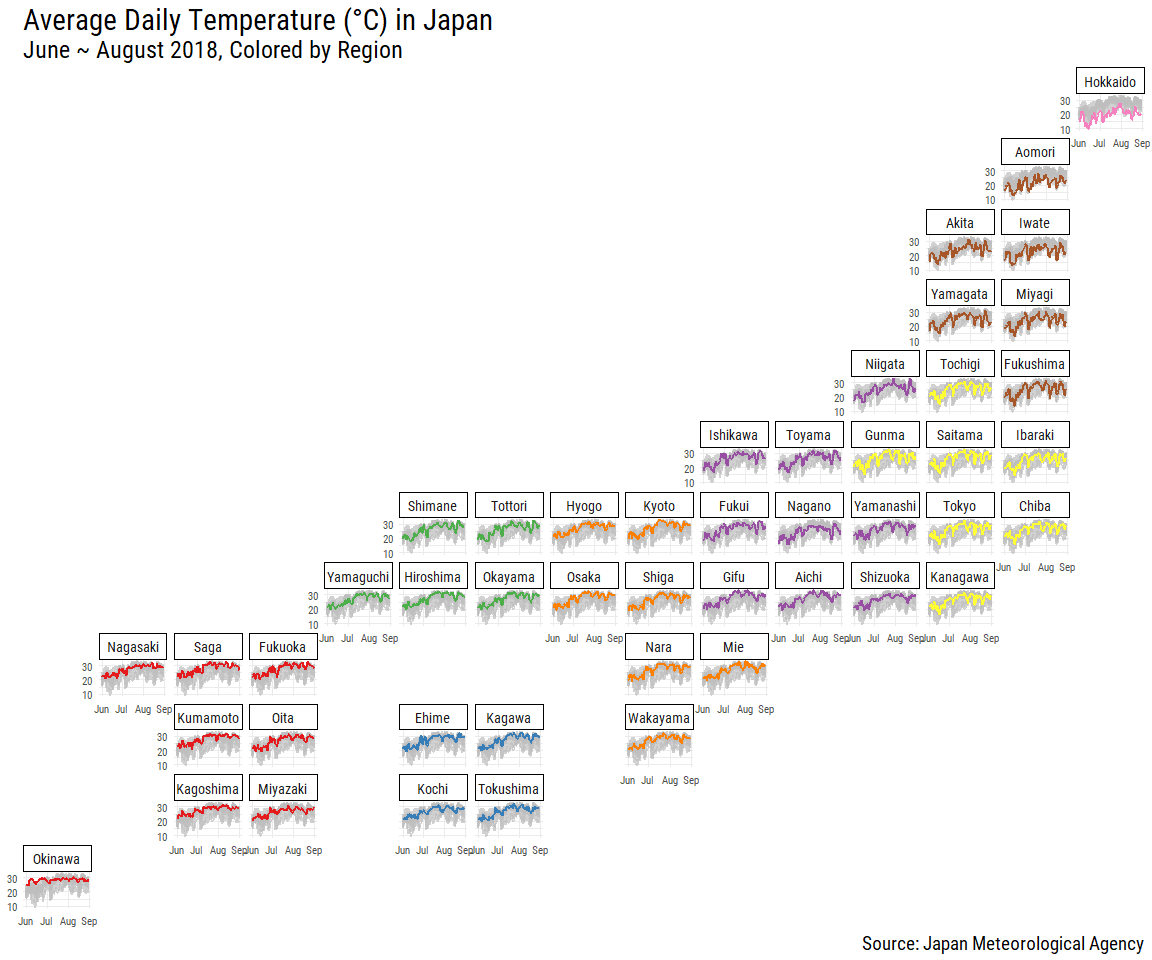
As Japan is such a thin and long country you can really see the differences in temperature between the southern and northern prefectures (Small reminder that I am using the capital city’s temperatures to represent each of the prefectures!). Using geofacets we can properly see the differences while still maintain geographic fidelity due to the positioning of the facets. In this format, we can really see that Gifu (in the purple “Chubu” region) is an outlier compared to the other prefectures seen in the “top 5” line chart a few graphs ago (Okinawa, Saga, Kumamoto, and Kagoshima all being part of the red “Kyushu” region)!
With the facet labels clearly showing the prefecture names we can now place both the geography and the name together.
Conclusion
The beginning of this blog post showcased some of my attempts in R at recreating some cool weather visualizations I saw on the internet. In the following sections I went through two different ways to gather Japanese weather data from the riem and jmastats packages. In the last section I created some exploratory graphics with the gathered data to raise questions about the data and different ways to present weather data.
With Autumn now settling in and the rainy days to come, I’ll end this blog post with a picture of a teru-teru-bouzu. These are handmade dolls made of white paper/cloth (usually tissue paper) which are basically talismans to prevent rain and to wish for good weather in Japan.
Thanks for reading and see you next time!
